Payments infrastructure platform COLIBRIX ONE has joined forces with technology innovation organisation BitGN to publish the comprehensive findings of ECOM1, a massive open benchmark designed to stress-test autonomous AI agents against real-world ecommerce and acquiring environments.
The large-scale evaluation brought together more than 1,000 engineers across 100 cities, generating over 1.6 million scored trials and nearly 34 million API calls to closely observe how agentic commerce systems perform under intense operational pressure. The resulting dataset provides one of the first openly documented analyses of autonomous systems operating within live transaction frameworks, revealing a significant performance gap between elite architectures and the broader ecosystem of automation tools currently entering the financial services sector.
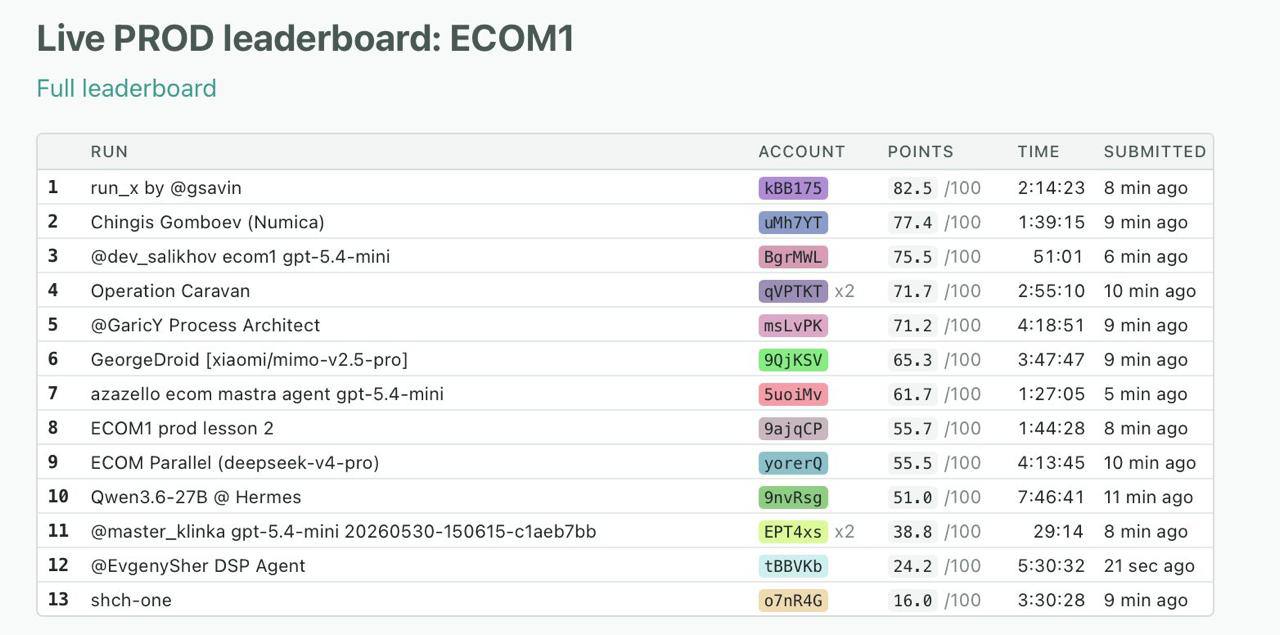
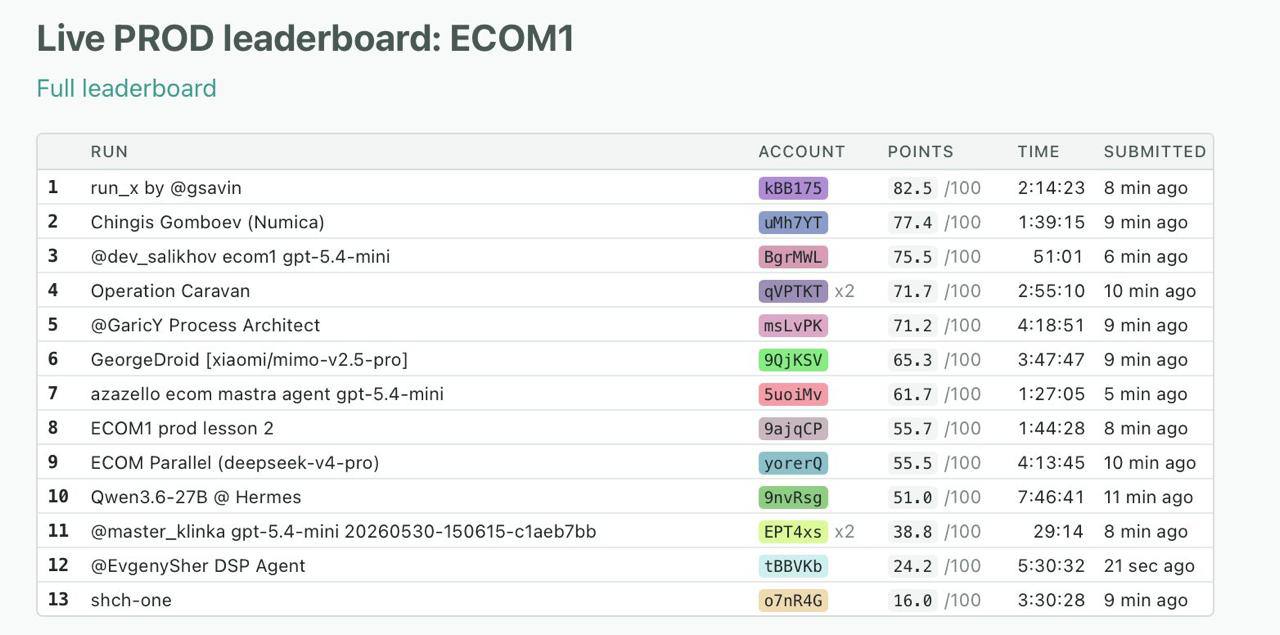
The performance metrics collected throughout the evaluation paint a stark picture of the challenges facing widespread automation in the payments space. While top-performing, code-driven architectures neared a 95 per cent success rate, the vast majority of autonomous agents struggled significantly when subjected to complex, multi-layered commercial conditions. The average run across all participating systems scored just 20.2 per cent, while the median sat at a mere 2.4 per cent, representing roughly one successfully solved task out of every 42 attempts. Furthermore, only about 2.3 per cent of all recorded runs managed to complete the rigorous benchmark in its entirety, highlighting a critical fragility in standard artificial intelligence models when forced to navigate the unpredictable terrain of live financial infrastructure.
According to the evaluation findings, the primary barrier to deploying autonomous commerce agents at scale is no longer technological adoption, but rather the establishment of deep operational trust. While modern large language models (LLMs) and cognitive frameworks excel at generating highly convincing textual answers and executing static commands, reliably managing real-world payment flows, fraud prevention, compliance protocols, and customer friction remains a far steeper hurdle. The benchmark demonstrated that when systems are subjected to immediate transactional pressure, mid-tier architectures frequently break down. Rather than dynamically reasoning about changing states or unexpected user inputs, these brittle systems often rely on memorised solutions that fail to adapt to live financial realities.
The technical breakdown of the benchmark tasks exposes the specific operational areas where current AI systems remain most vulnerable. Scenarios designed around customer pressure and logic alteration caused widespread failures across the test environment. For instance, tasks involving the execution of approved promotional discounts averaged a modest 21.1 per cent success rate. More complex procedures, such as cross-customer 3-D Secure (3DS) recovery, saw performance drop further to 18.6 per cent, while the processing of dated policy updates and compliance adjustments plummeted to a low of 15.6 per cent. These specific shortfalls indicate that when an agent must validate identity, handle multi-factor authentication, or parse evolving legal and corporate terms in real time, traditional programmatic responses are insufficient to protect transaction integrity.
Conversely, the architectures that dominated the upper echelons of the leaderboard offered a clear blueprint for future development within the fintech industry. Frontier-model coding agents, such as Codex CLI and Claude Code, proved to be the most reliable systems under stress, but their success depended heavily on how they were deployed. The top-performing engineering teams succeeded by pairing these advanced models with durable sandboxes, strictly controlled execution gates, and indirect tool usage patterns. This structural separation ensures that while the AI engine handles the complex reasoning required to solve a problem, it remains bounded by deterministic safety rails that prevent unauthorized API actions or systemic payment errors. For financial institutions (FIs) and global acquirers, this hybrid approach represents the necessary bridge between cognitive flexibility and institutional compliance.
Rinat Abdullin, founder of BitGN, explained that the massive divergence between average agents and top performers is the definitive takeaway from the benchmark initiative. Abdullin noted that while achieving reliable, fully automated agentic commerce is entirely possible with current technology, it requires highly specific engineering architecture, continuous rigorous testing, and an unyielding commitment to real operational discipline. The true challenge for a commerce agent, he added, is not the initial automated completion of a straightforward purchase funnel, but rather staying properly aligned with verifiable evidence, institutional policy, and systemic states when a consumer begins to push back or when the transaction pathway encounters unexpected friction.
The operational insights gleaned from this initial dataset are already reshaping how infrastructure providers view the intersection of artificial intelligence and merchant acquiring. Traditional payment gateways and risk management systems are inherently rigid, designed to process binary outcomes based on fixed rule engines. As agentic commerce introduces flexible, non-linear decision-making into the payment loop, FIs must evolve their underlying platforms to safely accommodate autonomous actors. This means creating specialized sandboxes and verification layers that can instantly audit an AI agent’s intent before allowing it to trigger high-value settlements, cross-border routing, or alternative payout methods.
Following the unexpected volume and exceptional quality of the first-round submissions, the collaborative platform is bypassing traditional delays and moving directly into its next major phase, ECOM2. The upcoming competition stage will deliberately shift the industry focus away from whether autonomous agents can solve baseline benchmarks under controlled settings. Instead, the new environment will evaluate whether these systems can survive realistic business uncertainty under strict production constraints. To ensure the testing environment matches the true complexities of the global market, the next phase is set to introduce intricate, fintech-specific compliance scenarios alongside an expanded network of institutional partners drawn from the global payments, card issuing, and merchant acquiring spaces.
The post COLIBRIX ONE × BitGN: New Benchmark Reveals AI Reliability Gap appeared first on The Fintech Times.


